算是去年写代码中最有意思的事了,记录一下。
缓存
1、缓存
位于速度相差较大的俩种硬件之间,用于协调俩者数据传输速度差异的结果,均可以称为Cache。其本质就是以空间换时间。
2、为什么要用缓存
- 提升访问性能
- 降低网络拥堵
- 减少后端负载
- 消除数据库热点
- 可预测的性能
在缓存预热的情况下,这个接口能响应多少性能其实是可以计算出来的。
- 增加系统可扩展性
缓存的特征指标
1、命中率
命中率 = 返回正确结果数 / 请求缓存次数
命中率越高,缓存使用效率越高
2、最大空间
缓存中可以存放的最大元素的数量
3、缓存生存时间TTL
缓存可以存活的时间,超过时间就失效
4、缓存清空策略
缓存可使用的存储空间有限,占满后就需要清除一些缓存,清空策略就决定了要清空哪些缓存:
FIFO(first in first out):先进先出,最先进入缓存的数据会被优先被清除掉,比较缓存元素的创建时间, 优先保障最新数据可用LFU(less frequently used):最少使用,根据元素的被使用次数判断,使用次数较少的数据将被删掉LRU(least recently used):最近最少使用,假设最近最少使用的那些信息,将来被使用的概率也不大,根据数据最后一次被使用的时间戳来决定,把最老的数据删掉【如何实现?面试题 】- 定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除
- 惰性过期:只有当访问一个key时,才会判断该key是否已过期,过期则清除
- 最长过期:根据过期时间,清理最长时间没用过的
- 最近过期:根据过期时间,清理即将过期的
- 随机过期清理:根据过期时间,任意清理一个
- 随机清理:无论是否过期,随机清理
缓存常见的问题
缓存失效
问题描述
在正常情况下,一些数据会被放在缓存里,等到后端服务系统查数据,首先会查缓存,如果缓存数据不存在,就进一步查DB,最后查到数据后回种到缓存并返回。但在某些情况下,比如说缓存剔除机制,会在下一次查询之前就把数据删除了,导致此次查询并没有走缓存。
分析
在某些特殊情况下,如果需要在同一时刻批量将数据写入缓存,如大促商品,那么由于设置同样的过期时间,在某一时刻这一大批的数据会同时失效,请求全部落在数据库上
解决方案
思路:不让相同业务中的所有数据都使用同一固定过期时间,在预设固定过期时间上再加上随机过期时间
expired time = base expired time + random time
缓存穿透
问题描述
用户用非法数据请求,缓存和数据库都没有要请求的数据,这样每一个请求都会落到DB。
分析
- 编码的时候只考虑了
happy path,对异常访问和特殊访问考虑不周 - 用户用不存在的
key访问,首先在cache里查不到这个数据,之后会落到数据库,发现数据库中也没有,会返回空。之后每一次用这个非法key去查询,都不可能命中缓存,也都会落到数据库。如果某一时刻,有大量的非法请求,会影响系统正常服务
解决方案
方案一:返回空值(特殊值代表空值)+ 提前校验
- 查询这些不存在的数据时,在第一次查询完数据库后虽然没查到结果,仍然将这个
key写到缓存中(可以是本地cache),只是这个key对应的value是一个特殊设置的值用于代表空值 - 另外,在请求的最上面就进行校验,通过一些规则过滤掉非法数据
缺点:会影响正常cache命中率
方案二:BloomFilter
构建一个BloomFilter缓存过滤器,记录全量key,请求到达时,通过BloomFilter判断这个key是否存在,如果不存在直接返回即可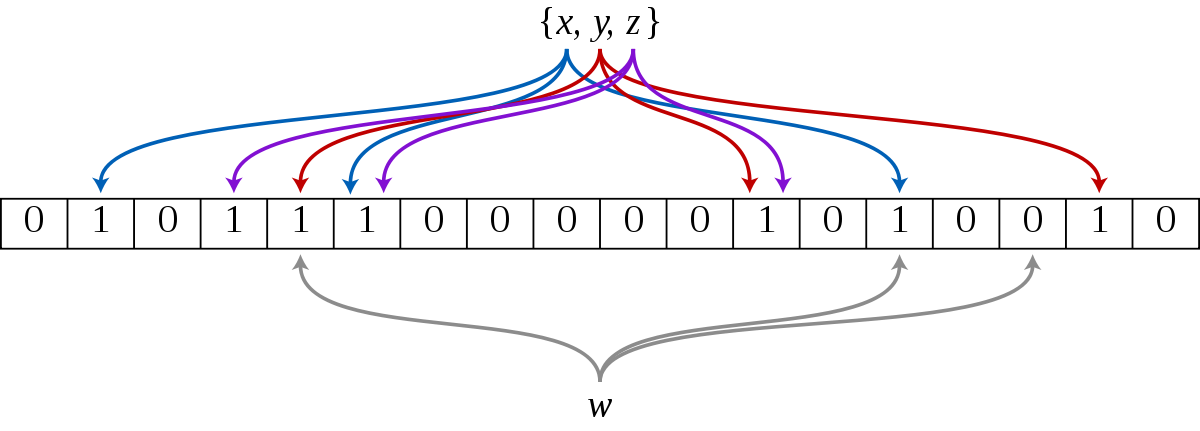
BloomFilter简单原理:
- 分配一块内存空间做
bit数组,数组的bit位初始值全部设为 0 - 加入元素:用
k个相互独立的Hash函数计算,然后将元素Hash映射的k个位置全部设置为1 - 检测
key:仍然用这k个Hash函数计算出k个位置,如果位置全部为1,则表明key存在,否则不存在Google Guava里面有现成布隆过滤器实现
缺点:1. 有误识别率【可以增加多个BloomFilter提高识别率】 2. 删除元素困难
缓存雪崩
1、问题描述
部分缓存节点不可用,导致服务降级甚至系统不可用的情况
2、问题分析
缓存雪崩根据缓存实现方案有两种情况:
- 缓存系统不支持
rehash时的缓存雪崩 - 缓存系统支持
rehash时的缓存雪崩
3、解决方案
Fail Fast开关机制:当高时延请求到达设置阈值后,对于请求快速失败,服务降级保核心服务;【只针对不核心的业务模块】- 增加缓存节点副本, 一个节点坏了可以从其他副本节点读取;【一致性哈希算法,尽量减少缓存数据的移动】
缓存数据不一致
问题描述
- 同一份数据,可能会同时存在
DB和缓存之中,DB和缓存中的数据也可能会不一致 - 如果缓存有多个副本,多个缓存副本里的数据也可能会不一致
分析
- 主要原因:更新缓存出现异常
- 更新数据库成功后缓存更新失败,数据库是最新数据,缓存中仍是老数据
- 更新多个缓存副本时其中一些副本更新失败,导致一些节点是新数据,一些是老数据
需要考虑分布式情况下的数据复制情况
解决方案
- 加入
retry机制尽可能地减少缓存更新失败,如果重试失败,要将失败的key想办法记录下来,再次访问时要使这些数据 - 将缓存数据
ttl根据需求适当调短,让缓存数据过期后可以从数据库重新加载,确保最终一致性
热点数据缓存问题
问题描述
在真实系统中数据会有冷热之分,如微博热搜,爆款商品,最新的新闻一定是访问频率最高的数据,这些都是热点数据。在某个时刻大量用户同时去访问热点数据,那么热点数据所在的缓存节点就会压力山大
分析
主要原因:大量请求同一个hot key,流量集中到一个缓存节点机器,缓存机器很容易到达到物理资源极限(物理网卡、带宽、CPU)
解决方案
最重要的一点是要找到热点数据,提取防范。
找到后可以提前预热,如设置多级缓存 + 多副本,另外也可以考虑到将热点数据分散到多个不同的缓存节点
并发竞争
问题描述
- 在多个线程/进程中有大量并发请求获取相同的数据,而恰好数据因为种种原因在缓存中不存在,导致并发查询
DB - 有不同的
client同时对同一个key设置不同的值
分析
主要原因:线程/进程之间没有协调机制
解决方案
串行化:分布式锁、消息队列
缓存读写更新模式
Cache Aside Pattern
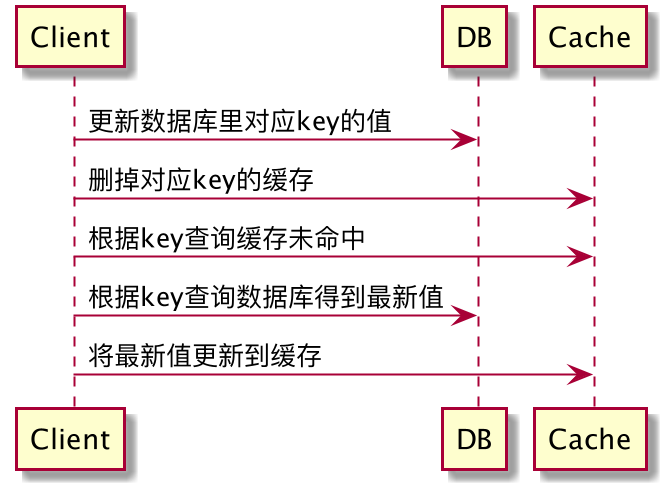
1、工作流程
读数据:
- 命中缓存:从Cache中取到数据后返回
- 未命中缓存:先从Cache中取数据,如果没有得到,则从数据库中取数据,成功后放到缓存中并返回给用户
写数据:
先把数据存到数据库中,成功后再让缓存失效(删除缓存)
2、适用场景
对数据一致性要求比较高的业务,或者是缓存数据更新比较复杂的业务,这些情况都比较适合使用 Cache Aside 模式
3、详解
(1)为什么先操作数据库,然后再操作缓存?
并发写时无法保证时序,可能出现数据不一致
(2)为什么删掉缓存,而不是更新缓存?
在读写并发时,可能出现数据不一致
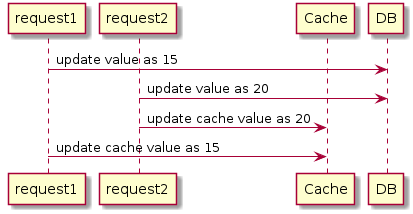
4、缺点
可能会出现数据不一致的情况。比如说:
一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去
5、解决方案
- 加分布式锁串行化
- 设置较短
ttl让缓存较快过期
Read/Write Through Pattern

在Cache Aside模式下,业务系统需要同时维护Cache和DB两个数据存储,过于繁琐。应该设置一个存储服务组件代理完成对Cache和DB的读写操作。
1、工作流程
写数据:
- 先查缓存,如果在缓存不存在,两种策略
no-write allication:只直接更新db,不会写入缓存(更为常用)write allication:先更新Cache,然后通过存储服务组件更新DB
- 如果数据在
Cache中,则先更新Cache,然后通过存储服务组件更新DB
读数据:
- 先查询缓存,如果数据在缓存存在则直接返回
- 若不存在,由存储服务组件从数据库中同步加载数据到缓存中
2、适用场景
对系统有较高隔离性要求,数据有冷热之分的业务
Guava中的Loading Cache比较像Read Through
3、缺点
同步写数据库延迟较高
Write Behind Pattern
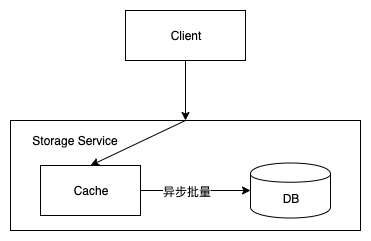
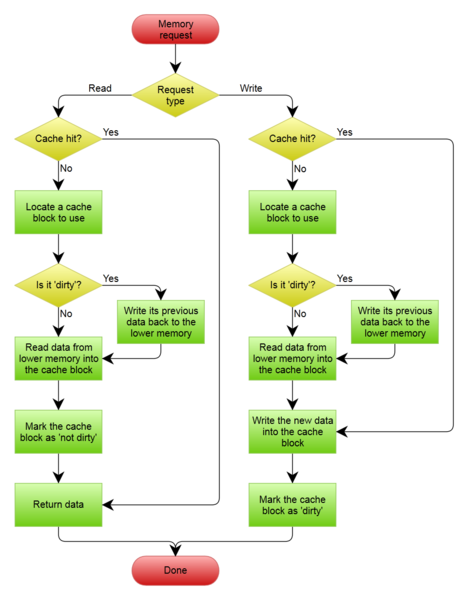
1、介绍Write Behind Pattern是想在更新数据的时候,只更新缓存,不更新数据库,缓存会异步批量更新数据库
2、适用场景
大量写请求,可以合并写请求的业务
3、缺点
数据一致性差,存在数据丢失的可能
https://zh.wikipedia.org/wiki/%E7%BC%93%E5%AD%98
https://coolshell.cn/articles/17416.html
https://mp.weixin.qq.com/s/koKDacEH1v9M6B-XDFfuOw