今天在看到Redis的IO多路复用时,顺便总结一下在Unix上各个IO模型,以及他们在网络服务中的应用过程。
背景
首先,我们先想想计算机在互联网的工作流程。我是做后端的,所以经常接触到客户端发送一个Http请求,因为应用进程监控指定的端口,所以计算机会按照之前该进程的要求,处理数据。
现在我们来细化一下这个问题:其实客户端与服务端的交互,都是通过Socket来交互的,进程读取Socket的数据,然后向Socket写入数据,接着用户就可以看到服务端返回的数据了。
这里我们要想一个问题:
Socket究竟是什么?为什么我们读它的数据,就是读用户输入的数据;向它写数据,用户就可以读到数据?
其实,在Unix系统下Socket就是一个文件而已。假设一个进程监控某个端口,后来客户端发送Http请求到这个网络端口,
进程将这个链接变成一个Socket,当然就是Unix系统上的一个文件而已,这些文件都会有File Descriptor,当用户持续向服务端发送消息时,其实就是在往这些Socket文件写入数据,
当它写完之后,就需要CPU来告诉进程,数据准备好了。通常情况,一个后端服务会创建很多的Socket文件,这就需要CPU去定时检查这些Socket文件,如果这些Socket文件中有部分可读的话,就需要通知进程来读取。
所以,Unix下面的IO模型都是为了尽可能的减少中断CPU执行,因为每次CPU从其他任务转来检查这些Socket文件的时候,都需要上下文切换,而这些代价都是挺大的。
Unix网络编程中定义的五种IO模型
BIO:阻塞IO
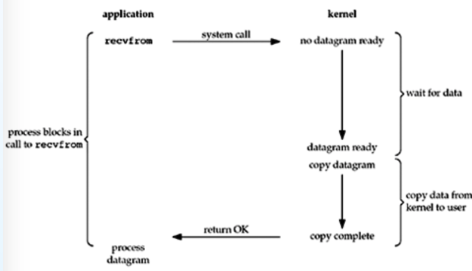
在这种IO模型下,程序会阻塞在系统读取数据的那行方法下。此时即使CPU执行到该进程,也只能在这里等待。
NIO:非阻塞IO
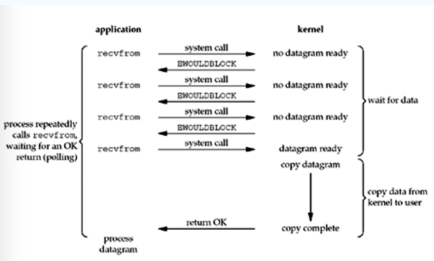
程序不会卡在读取数据的方法下,最起码不会让CPU在那白白的等待。但也是有缺点,CPU可能会浪费时间在轮询上。
MIO:IO多路复用
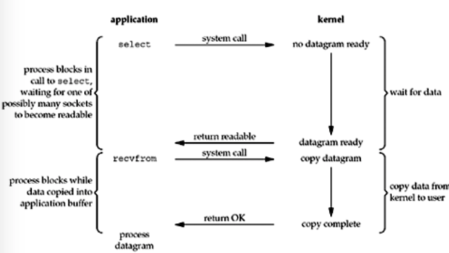
IO多路复用是指程序在监控多个IO事件时,只需要通过一个方法来监控。例如,上面的BIO、NIO来监控某个IO事件时,可能就要写一个方法了,也就是你监控n个IO,你就需要写n个方法。
而IO多路复用是指自己监控多个IO事件,当其中有IO准备好了的时候,就通知指定的进程。
SIO:信号驱动IO
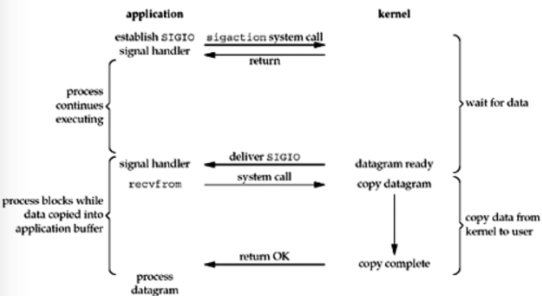
AIO:异步IO
实现IO多路复用的方法
select、poll
select、poll相同点是都会监控很多fd,当这些fd中有准备好的IO事件时,就会通知CPU。但是它不会告诉具体是哪一个FD准备好了,需要CPU自己再轮询一遍FD才知道哪些IO准备好了。
不同点就是:select只能创建指定大小的监控队列,即无论你需要监视多少个fd时,它都会创建长度定长的数组。比如说,你只需要监控3个fd,但你还是会创建长度为1024的数组,然后会创建指定fd位置上存储;poll是可以动态创建大小的监控队列,你需要监控三个fd,就只创建长度为3的数组。
epoll
epoll比上面俩个方法都好一点,当它监控多个fd,当其中有哪个fd准备好了时,它会告诉CPU哪些fd准备好了。CPU就不需要再去轮询这些fd,检查哪个fd准备好了。
https://www.ituring.com.cn/book/650
https://jvns.ca/blog/2017/06/03/async-io-on-linux--select--poll--and-epoll/
https://devarea.com/linux-io-multiplexing-select-vs-poll-vs-epoll/#.XlerOZMzZ3l