数据库是用来存储海量数据的软件。但同时,还需要保持尽可能的高效率。而数据库是如何保持高效率的检索?答案就是索引。
很早期的时候,文件的存储是需要花费大量的人力、物力,而且在检索的时候,可能也不是那么高效。可以想象一下,你在图书馆找书的过程,书本的摆放就需要有专门的人去做,当你想找某本书的时候,你通常会先获取它的排列号,然后根据这个号码在广泛的图书馆查找。其中,这个排列号就很类似数据库中的索引。
说白了,就是每一个数据都对应一个唯一id,所有数据的唯一id就是索引。我只要知道数据的索引是多少,我就能够快速定位到这个数据的物理位置。
索引如何实现
现在我们相当于有了一堆物理地址的索引数据,我们现在就要想如何快速的检索这些索引数据来找到数据。
线性表
线性表可以做到查找是常数时间,但是增加、删除、更新操作却是O(n)的,而且对与海量数据来说,线性表是很难支持的。但是你看后面的B树每个节点内部的元素其实就有点类似线性表。
哈希表
在理想情况下,哈希表可以做到查找、增加、删除、更新操作都是常数时间,但是它本身是无法支持范围查找的,而且对于海量数据来说,哈希表也是很难支持的。但如果只是少量的数据,用哈希表来做索引也是挺不错的。
红黑树

红黑树是一棵平衡的二叉树,它任意节点的左子树都⽐根节点小,右子树都比根节点⼤。它的查找时间复杂度是对数。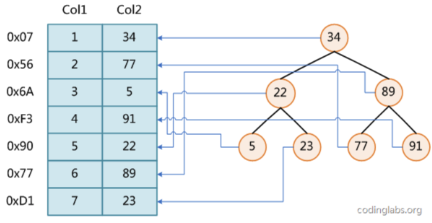
为什么索引不采用红黑树
这是一道面试常问题,为啥MySQL索引采用B+树,而不使用红黑树。答案是因为:在磁盘IO的前提下,使用B+树来存储索引比红黑树更有效率。
主要是为什么呢?
对于衡量MySQL此次操作快不快,通常是取决于它执行了多少IO操作,如果IO次数越少,就说明这次的执行效率非常高。而现在的计算机都是三层架构,即CPU => 内存 => 磁盘,这每层架构之间的速度差异非常大,所以普遍都会加上缓存。比如说:CPU里面就有一级缓存、二级缓存的东西,内存与磁盘之间会留有buffer。所以,当你想读取某块磁盘数据时,根据局部性原理,计算机会尽可能的把周围的数据也传输给你。
想象一下,你的索引目标数据在树的底层,如果你是红黑树的话,你的层级会非常高,要想确定目标数据的索引,你可能就要多读取一些根本没必要的数据。而如果你是B+树的话,每一层的数据都非常多,很有可能一次IO操作,你就确定了目标数据的索引。这也是为什么IO操作相关的数据结构都要求树的层数尽可能的低。
B树
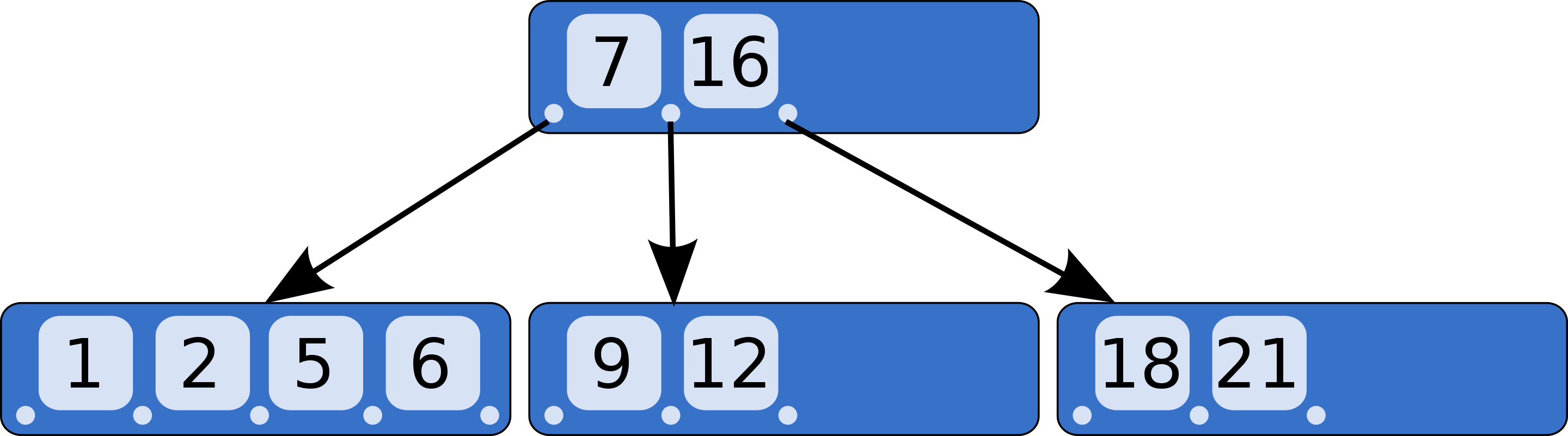
B树是一棵⾃平衡的、⾼度很低的多叉树。它的order(度)表示每一个节点最多有多少个子节点。每个节点的子节点数量量在[order/2, order]之间。
1、B树的优点
- 节点留有一定空间(浪费了一定空间)
- 因此无需频繁旋转
- 当插入时只需要移动少量数据
- 支持范围查询
- 树高度非常低,使得能够一次获取大量数据
- 对磁盘友好——数据预读
B+树
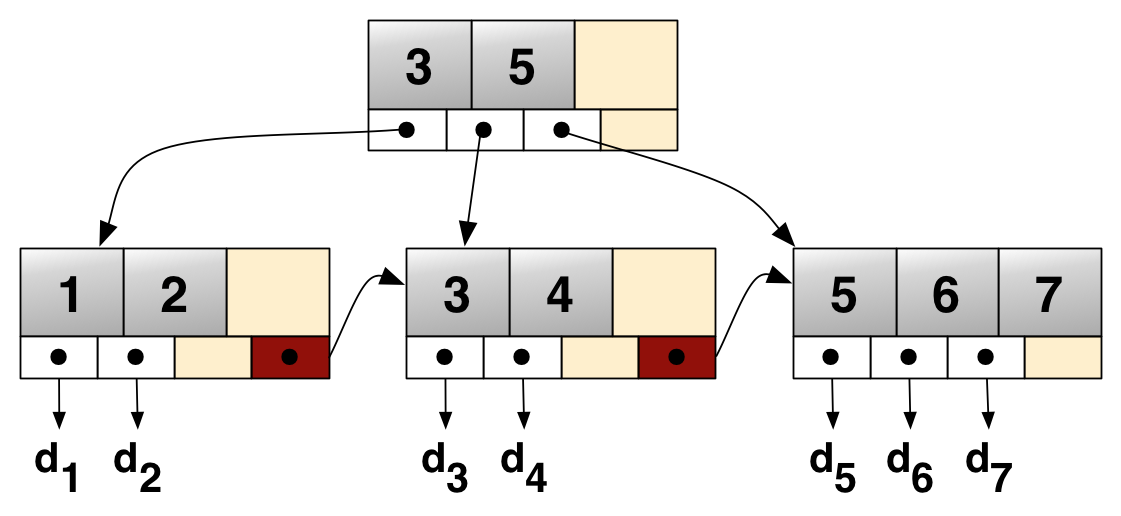
1、对B树的改进
- 非叶子节点只存放索引,所有的数据放在叶⼦节点
- 为每个叶子节点增加连接的指针
2、特点
- 叶⼦节点包含了全部的数据
- 非叶子节点只存放索引,因此可以容纳更多索引
- 树的高度更低
- 每次查询都必须到叶子节点
- 性能稳定
- 叶子节点的指针使得范围查询更⽅便
乱七八糟的索引的名称
主键索引
主索引一般就是你表的主键。
如果没有主键的话,会选择一个唯一列做为主索引
其实就是用这些主键值比较大小,然后做成一个B+树。检索的时候,就会到它的叶子结点找到数据的地址;
普通索引
有的时候,你可以为某个列单独建立一个索引。
然后根据这个列的数据,比较大小,然后做成一个B+树。检索的时候,就会到它的叶子结点找到其主索引的位置(这个是InnoDB的实现方式)。
联合索引
你还可以把某几个列一个作为一个索引。然后这几个列的数据,组成一个N元组tuples,比较大小,然后做成一个B+树,它的叶子结点就是存储这个N元组。
考虑一下?联合索引会导致数据量过大,这样就又可能导致B+树的高度增加
联合索引的最左匹配原则
聚簇索引和非聚簇索引
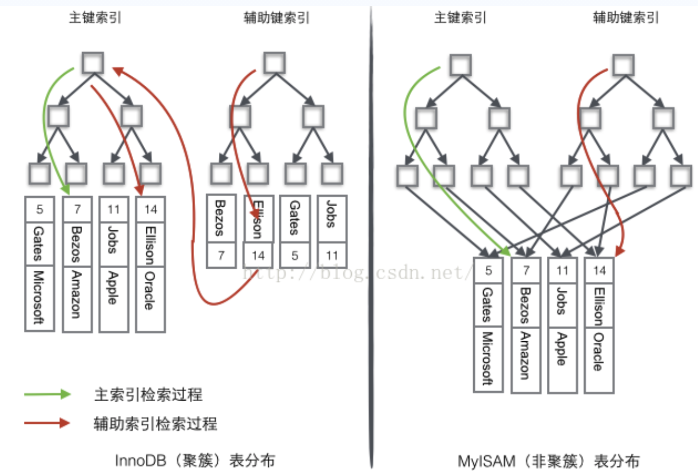
1、非聚集索引
MySQL中的MyISAM引擎采用的就是非聚集索引,它叶子节点存储的都是数据指针。
2、聚集索引
MySQL中的表采用InnoDB引擎的话,其主索引就是一个聚集索引。它叶子节点存储的就是数据本身。
3、覆盖索引
假如select的数据列在索引中不存在,就需要重新便利主索引的B+树,去找到真实数据。如果有的话,就是覆盖索引。可以参考下面: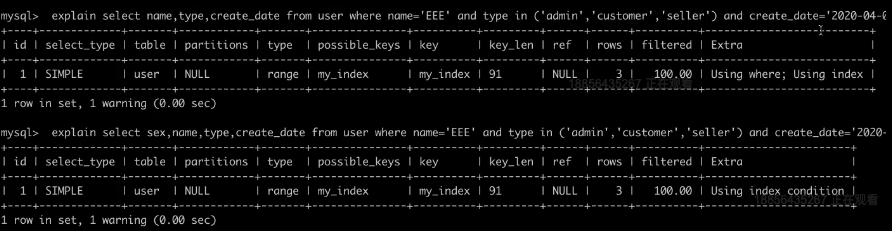
https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#explain-extra-information
Using index、Using index condition
4、回表查询
聚簇索引如果通过辅助索引来查询数据的话,会走俩次B+树查询,这种过程称为回表查询
https://dev.mysql.com/doc/refman/8.0/en/optimization-indexes.html
https://www.zhihu.com/question/273489729/answer/382181550
https://coolshell.cn/articles/4671.html
https://www.cs.usfca.edu/~galles/visualization/BTree.html
https://zh.wikipedia.org/wiki/%E7%BA%A2%E9%BB%91%E6%A0%91
https://zh.wikipedia.org/wiki/B%E6%A0%91
https://zh.wikipedia.org/wiki/B%2B%E6%A0%91